Inference Engine for Microcontrollers¶
Plumerai’s inference engine provides fast execution of deep learning models in tiny memory spaces. It reads in 8-bit TensorFlow Lite FlatBuffers (.tflite) and generates a library that includes the model, runtime, and optimized kernels. The inference software has been benchmarked on Arm Cortex-M microcontrollers as the fastest and most memory-efficient in the world. This is without additional quantization, binarization or pruning. The model accuracy stays exactly the same.
You can find more information about the inference engine on our blog and try it out in our online benchmarker to find out how fast and memory efficient it is for your model. Please get in touch with our team if you don't have access to the Plumerai Inference Engine yet.
Table of contents:
- Model format support: Overview of the supported input model formats.
- Layer and op support: Lists which neural network layers/ops are supported.
- Reporting and analysis: Information about the reporting and analysis options to better understand the combination of the inference engine with the supplied model.
- Correctness validation: Details on how to run in validation mode to ensure correctness of the inference model.
- Building and integration: Instructions on how to build the inference engine library and integrate it into an application using the C++ API or C API.
- Example models: Example TensorFlow Keras models for typical neural networks including details on how to quantize them and save them to be used for the Inference Engine Generator, including LeNet, MobileNetV2, an LSTM and a GRU-based RNN.
Overview¶
Below is a high-level overview of the compilation flow using the Plumerai Inference Engine. The main component is the Inference Engine Generator, a tool that takes as input a trained neural network and produces as a result a model-specific inference engine runtime library. This tool can run in the cloud or on a user's machine. This inference engine can then be used inside a user's application for final deployment onto a device.
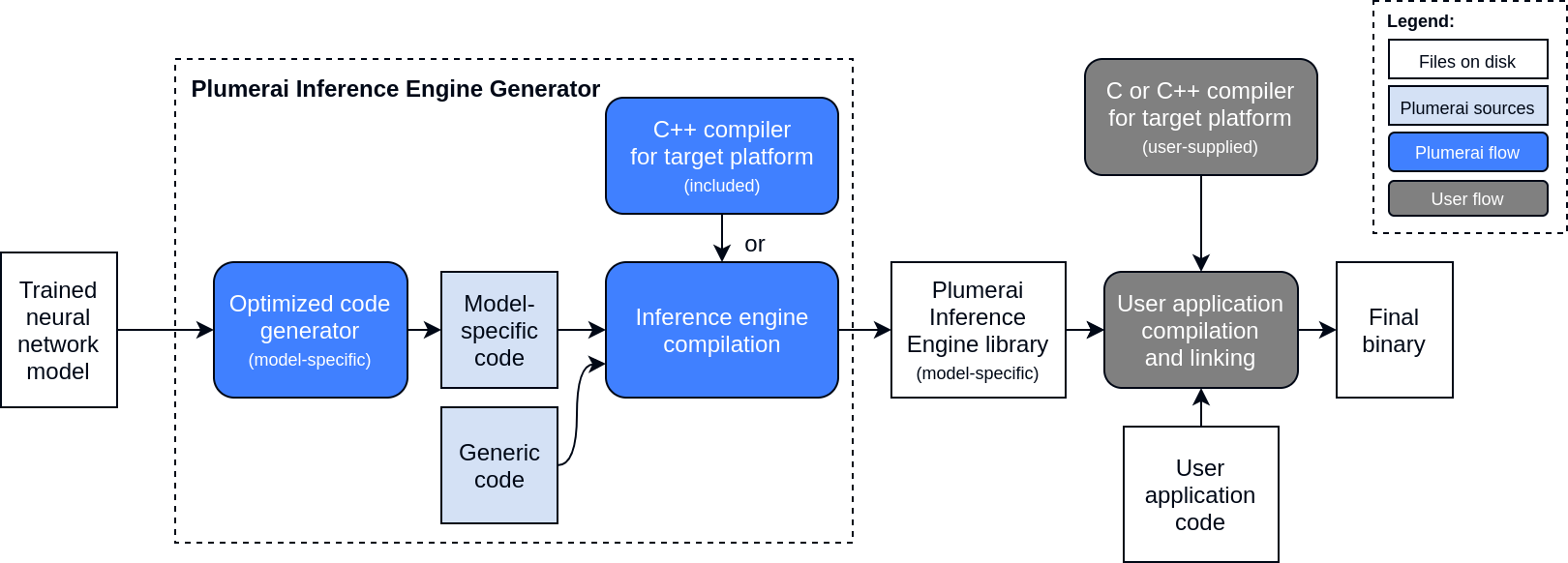
Or, in words:
- The Inference Engine Generator takes a neural network model as input. See the model documentation for more information on supported formats.
- The Inference Engine Generator internally generates optimized model-specific C++ code and combines that with generic support C++ code. It then compiles this using an internal GCC-based C++ compiler for the target platform.
- The Inference Engine Generator produces a model-specific inference engine runtime library and header files. These can be used in an application using the C++ API or C API.
This documentation contains information about both the Inference Engine Generator and about the resulting inference engine library and how to use it.