Plumerai VLM Text Search API¶
This document describes the API for the VLM Text Embedder and the Video and Text Matcher functionality. This is available through the plumerai_vision_language Python package.
These components are part of Plumerai Video Search and Plumerai Custom AI Notifications. See those product pages for architectural context and real-world usage examples.
For reference, the architecture diagram below shows how the text embedder and matcher fit into the overall system:
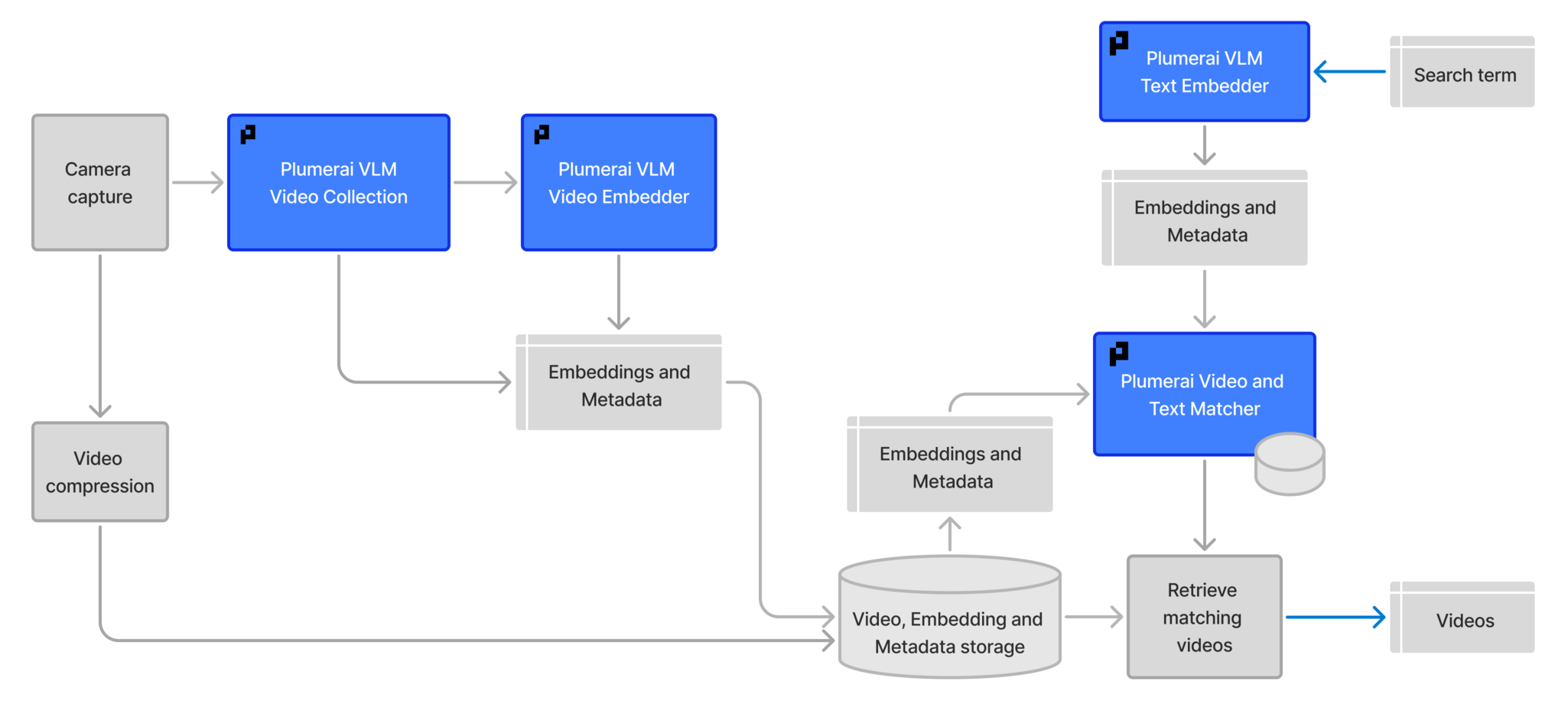
For the VLM Video Collection and VLM Video Embedder API documentation, visit this page for C++ and this page for Python.
Data types¶
TextEncoding¶
Raw bytes obtained from running encode_text.
VideoEncoding¶
Raw bytes obtained from running the VLM Video Embedder. This is input to the search and score_video functions.
IsMatch¶
Represents whether a video and search query match.
Allowed values:
YES: Video matches query. Evaluates toTruewhen used as a boolean.NO: Video does not match query. Evaluates toFalsewhen used as a boolean.MAYBE: Video may match query but is uncertain. Evaluates toTruewhen used as a boolean.
SearchResultMetadata¶
Metadata as used in the SearchResult and ScoreResult objects.
SearchResult¶
class SearchResult:
similarities: list[float]
is_match: list[IsMatch]
metadata: list[SearchResultMetadata]
The result as returned by the search function.
A higher similarity means the corresponding video is more relevant, and is_match indicates whether each result meets the match threshold.
The metadata.time field contains the time (in seconds) of the relevant part of the video for a search query. This is useful for displaying search results to users as the thumbnail can then be relevant for what they are looking for.
ScoreResult¶
The result as returned by the score_video function.
Functions¶
encode_text¶
Encode a text string into Plumerai's search encoding format.
Arguments:
- text: A string of text you want to encode.
Returns:
bytesof Plumerai'sTextEncodingobject.
search¶
Search a user's history for relevance to a given query string.
Arguments:
- user_history: The list of
VideoEncodingobjects from a single user you want to search over. - query: A search string e.g. "a cat in the driveway" or the
TextEncodingof a search string returned byencode_text.
Returns:
- A
SearchResultobject which contains the similarities and match values with respect to the given query.
score_video¶
Score a single video encoding against a text encoding.
Arguments:
- video_encoding: A single
VideoEncodingobject. - text_encoding: A single
TextEncodingobject as returned byencode_text.
Returns:
- A list of similarity scores between the video and each text encoding.
Example: regular video search¶
To run a search query, all relevant video encodings for a given user need to be loaded into memory. The search function then takes a user_history which is a list[VideoEncoding] (output from the VLM Video Embedder) and a search query which is a str or the bytes resulting from calling encode_text. It is good practice to cache common search queries using encode_text and then read these from cache in order to do a search - this reduces latency and compute because search no longer has to encode the text.
from plumerai_vision_language import IsMatch, search
# Read relevant items from storage / database here
plumerai_video_encoding1 = ...
plumerai_video_encoding2 = ...
user_history = [plumerai_video_encoding1, plumerai_video_encoding2]
search(user_history=user_history, query="cat")
# Example output:
# SearchResult(similarities=[0.3192299008369446, 0.032717231661081314], is_match=[IsMatch.YES, IsMatch.NO], metadata=[SearchResultMetadata(time=3.813), SearchResultMetadata(time=0.3333333333333333)])
The function search returns a SearchResult object which contains the similarities where a higher similarity means the corresponding video is more relevant and is_match which indicates whether each result meets the match threshold or other criteria such as metadata-based filters.
The Plumerai SearchResult object should be combined with video IDs to provide a user with results e.g.
import numpy as np
from plumerai_vision_language import IsMatch, search
user_history = ... # See the previous example
video_ids = ... # A list of video IDs corresponding to user_history
search_result = search(user_history=user_history, query="cat")
indices = np.argsort(search_result.similarities)[::-1].tolist()
processed_search_result = [
(video_ids[i], search_result.metadata[i].time)
for i, match in zip(indices, search_result.is_match) if match == IsMatch.YES
]
The object SearchResultMetadata.time contains the time (in seconds) of the relevant part of the video for a search query. This is useful for displaying search results to users as the thumbnail can then be relevant for what they're looking for.
Example: individual video scoring¶
You can also score a single video against a text query using the score_video function. This is useful for classifying videos for notification or UI features.
This is different to the search API in that information from other videos aren't available and so the scoring and thresholding are scaled differently.
from plumerai_vision_language import encode_text, score_video
queries = [encode_text("cat"), encode_text("person")]
# Read relevant items from storage / database here
plumerai_video_encoding = ...
[score_video(plumerai_video_encoding, q) for q in queries]
# Example output:
# [ScoreResult(similarity=1.2557752, is_match=IsMatch.YES, metadata=SearchResultMetadata(time=3.22)), ScoreResult(similarity=-2.490197, is_match=IsMatch.NO, metadata=SearchResultMetadata(time=0.149))]
Optimization: Text embedding caching¶
To reduce latency, a lookup table of common search queries is used.
For queries not found in the cache, the model dynamically encodes the text into an embedding. By default the encoding runs on a single thread which can be a bottleneck. You can set the PLUMERAI_NUM_THREADS (or legacy PLUMERAI_THREADS) environment variable to reduce the latency. For example, setting PLUMERAI_NUM_THREADS=8 will use 8 threads for encoding the text. PLUMERAI_NUM_THREADS=0 will use the number of physical CPU cores available.
Optimization: model loading¶
The respective models are loaded on the fly for each API function to save memory. If you need to preload the model then you can call the respective API function with some valid inputs.